简单认识KMV Sketch估算算法
2019-01-28 16:32:52
原创
大数据
算法
介绍
KMV Sketch是Theta Sketch算法的一种,简单来说,KMV Sketch是用来估算大数据中不重复元素的个数,例如某个网站的唯一身份访客数。本文简单翻译自datasketches的文档,用以说明该算法是如何进行估算的。
案例1
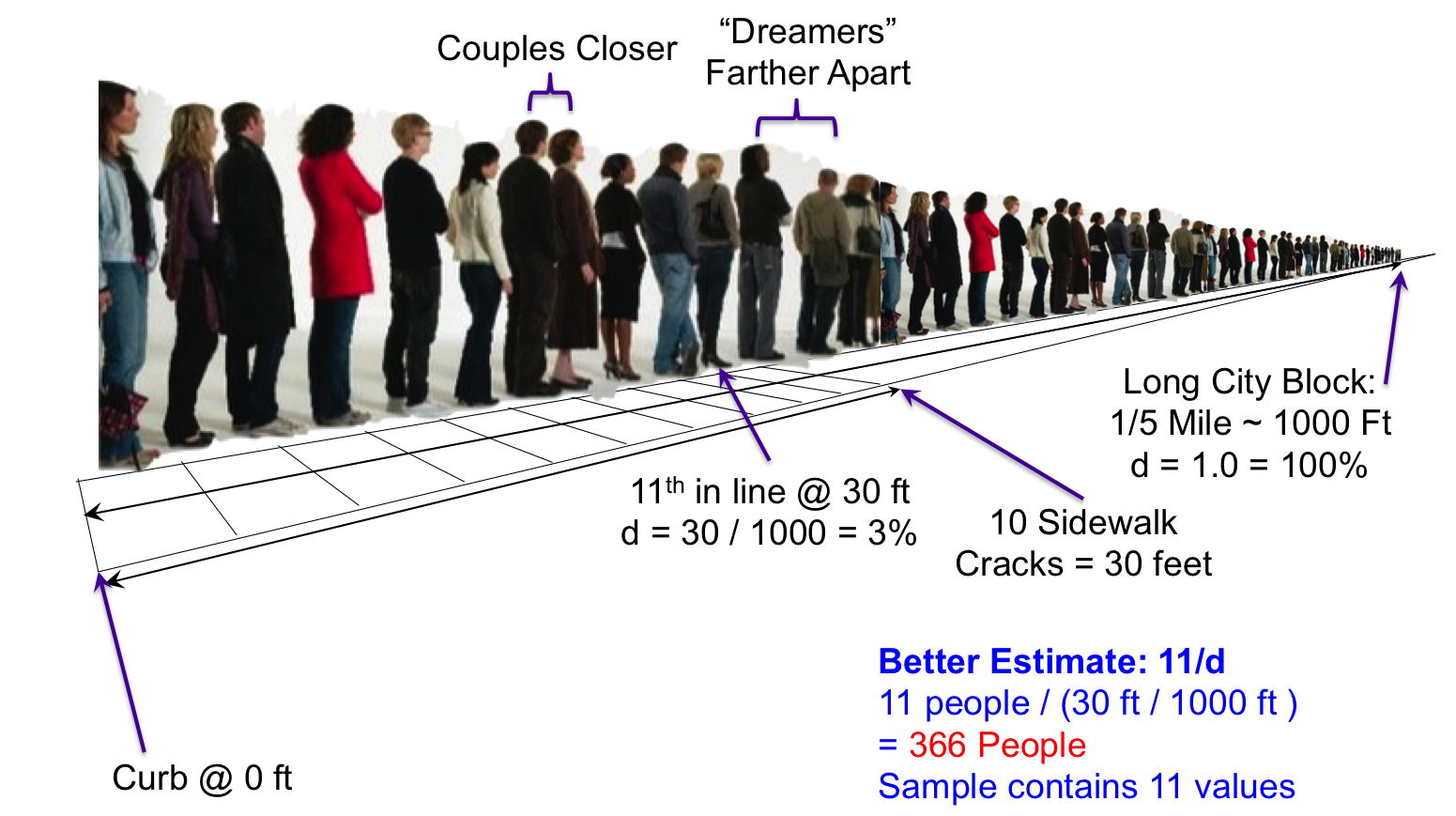
如果你去参加音乐会,你排在队尾,如何估计你的前面还有多少个人?如下图,整个队伍的长度是已知的为1000Ft,你与前一个人的距离为2Ft,那么可以简单的估算,整个队伍共有1000Ft/2Ft=500人,此时你用于计算的样本包含的人数为1人。

再次观察这个队伍,你发现人与人之间的距离并不是均匀的,你看到队尾的11个人一共占据了30Ft的长度,那么再次估算人数为1000Ft/30Ft*11=11/(30Ft/1000Ft)=366人,由于此次你用了11个人作为样本,估算值应该比之前更精确。
案例2
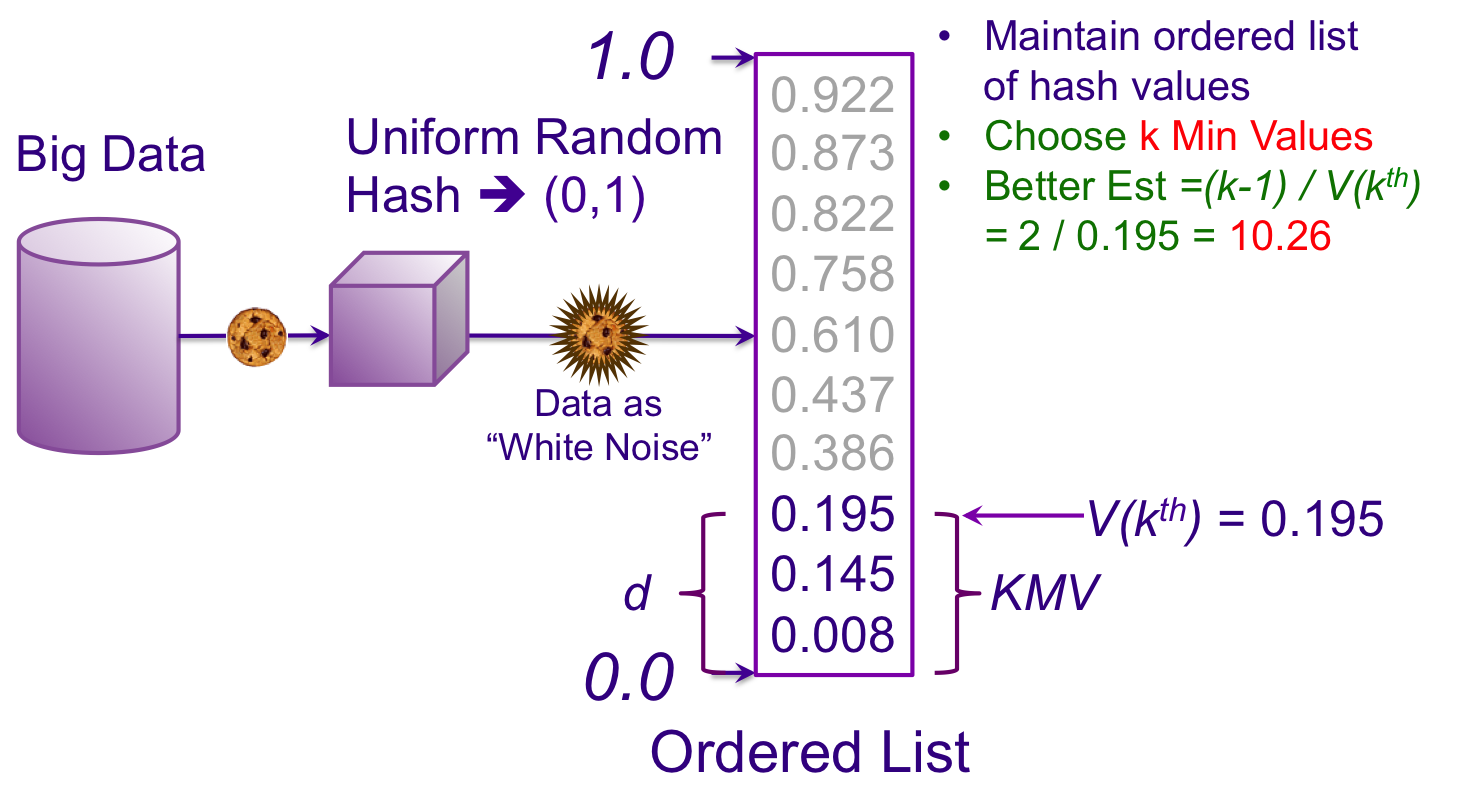
现在我们有一份大数据样本,包含的是访客的唯一id,为了简单说明原理,假设只有10个不同的id,我们还需要一个特殊的hash函数,它能将id映射成0~1之间的值,并且映射后的值是有序的,如下图所示:

如果选取最小的那个值作为估算样本,那么整体数量的估算值为1/0.008=125,如果选第4个数,即0.386作为样本,那么估算值为1/(0.386-0.195)=5。可以看到,在只有一个样本的情况下,估算值与真实值10差距较大。
参考估算排队人数的做法,我们同样选择多个样本来估算,例如选择最小的0.008/0.145/0.195这3个样本,此时估计值的计算方式为(3-1)/0.195=10.26,可以看到,距离真实值已经很接近了。
KMV估算法的计算原理就是这样,虽然很简单,但数学上可以严格证明该估计量是整体的无偏估计。

相关链接:什么是无偏估计?